上把打了个酱油快速走读了一下首次渲染流程,这把我们玩个核心,来看看 Vue 中最经典的部分:响应式数据原理。啥都不说,我们先上图:
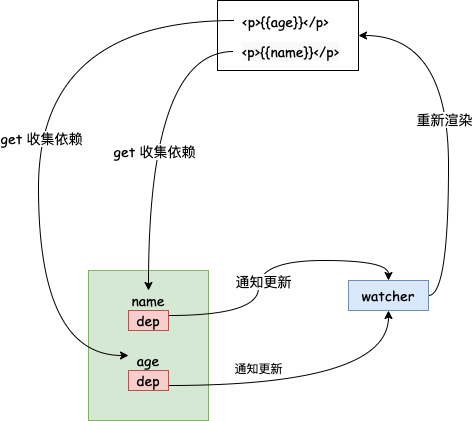
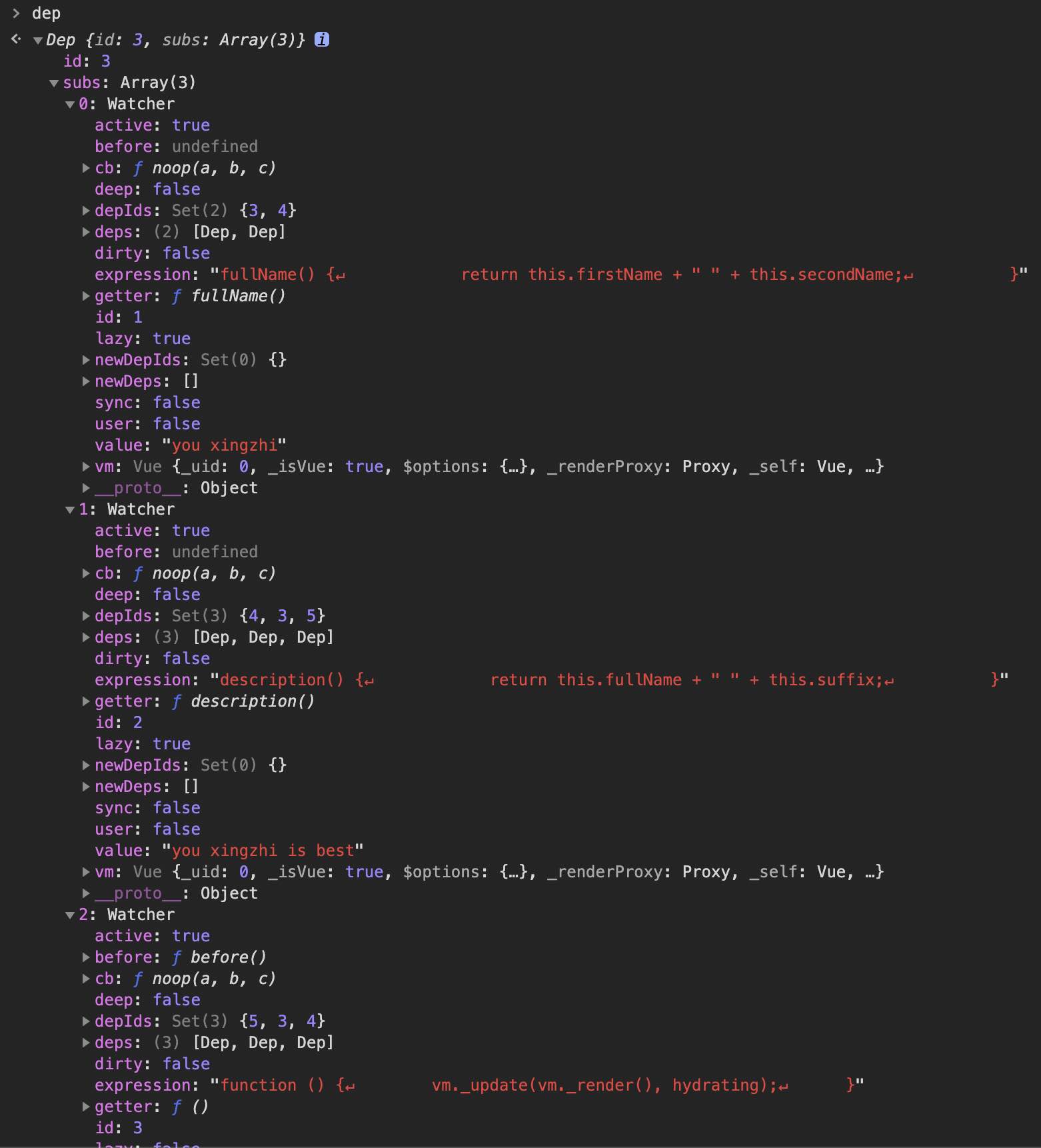
定义响应式数据
我们在初始化 Vue 的时候,会执行 initState(vm)
1 | export function initState(vm: Component) { |
这里最重要的是 initData 这个方法:
1 | function initData(vm: Component) { |
这里也没什么特别的,关键是 observe(data, true /* asRootData */) 这一句:
1 | export function observe(value: any, asRootData: ?boolean): Observer | void { |
这里也只是通过传进来的 value 实例化了一个 Observer 对象:
1 | export class Observer { |
这里分数组和对象分别进行了处理,我们先来看看 defineReactive:
1 | export function defineReactive( |
这里分别给数据定义了 get 和 set 方法,执行 get 方法的时候会进行依赖收集。
依赖收集
我们看看依赖收集做了什么:
1 | depend () { |
这里的 Dep.target 又是哪来的呢,其实它就是 Watcher 的实例。
1 |
|
上一章说了,在组件 $mount 的时候会初始化一个 Wathcer,
在 Watcher 初始化的时候会执行 this.get, pushTarget 将前Dep.target 设置为当前的 Watcher。同时,执行 this.get 的时候,还会调用 this.getter.call(vm, vm),这个 getter 就是构造函数中传递进来的 expOrFn,它是啥呢,它就是:
1 | updateComponent = () => { |
其中 vm._render 执行的时候会对数据进行取值操作,从而触发 defineProperty 中的 get 方法。
触发更新
当数据被赋值的时候会触发 set 方法,调用 dep.notify(),最后会调用 Watcher 类中的:
1 | update () { |
queueWatcher:
1 | export function queueWatcher(watcher: Watcher) { |
我们先看看 flushSchedulerQueue:
1 | function flushSchedulerQueue() { |
其他更多细节可以参考我们自己 DIY 的响应式系统。
这里我们看看数组是怎么处理的。
数组处理
1 | if (Array.isArray(value)) { |
我们先看看 protoAugment:
1 | function protoAugment(target, src: Object) { |
看来还得看看 arrayMethods:
1 | import {def} from '../util/index' |
我们举例来说说这一串的操作是干了个啥:
1 | [1, 2, 3] --__proto__--> arrayMethods --__proto__--> Array.prototype |
其中 arrayMethods 对 7 个数组方法进行了包装,使得在对数进行操作的时候可以通知 Watcher 进行更新。这里的 ob.dep 是个啥呢。比如说 data 中有这样一个属性 arr: [1,2],在对 arr 进行依赖收集的时候有如下代码,这里的 childOb.dep 和上文的 ob.dep 是同一个对象。
1 | ... |
具体来说,这里的 childOb 就是 [1,2] 这个对象经过 observe 返回后的 Observer 实例,它有 dep 属性。从这里可以看到它和 arr 拥有一样的依赖,即下面这两个操作都会触发通知相同的 Watcher 去更新:
1 | // 1 |
computed 的处理
1 | const computedWatcherOptions = {lazy: true} |
这里遍历了 computed 里面的每一个属性,并且为每一个属性初始化了一个 Watcher 对象。这样,当我们在 computed 里面访问 data 里面的属性时,就可以收集到依赖了。注意到这里传入了 { lazy: true },我们看看会有什么效果:
1 | this.dirty = this.lazy // for lazy watchers |
该属性仅仅是标记了当前数据是 “脏的”,并且不会立即求值。所谓 “脏的” 指的是当前值已经脏了,需要重新求值了,这个后面会再提到。
然后我们看看 defineComputed 做了啥:
1 | export function defineComputed( |
这里跑到了 createComputedGetter 这个方法:
1 | function createComputedGetter(key) { |
当我们第一次访问计算属性的时候会触发 get,由于 dirty 为 true,所以这里会走 watcher.evaluate 进行求值,并将 this.dirty 置为 false,这样下次再对 computed 进行求值的时候就不会执行 watcher.evaluate() 了,这样就实现了缓存功能。
1 | evaluate () { |
而当 computed 依赖的数据变化的时候,会触发 Watch 的 update:
1 | update () { |
这里仅仅是把 dirty 又重置为了 true 以使得下次对 computed 进行求值的时候重新执行 watcher.evaluate()。
缓存部分说完了,我们来看看下面这一段代码做了什么:
1 | if (Dep.target) { |
1 | depend () { |
这里有点难理解,我们用一个例子来说明:
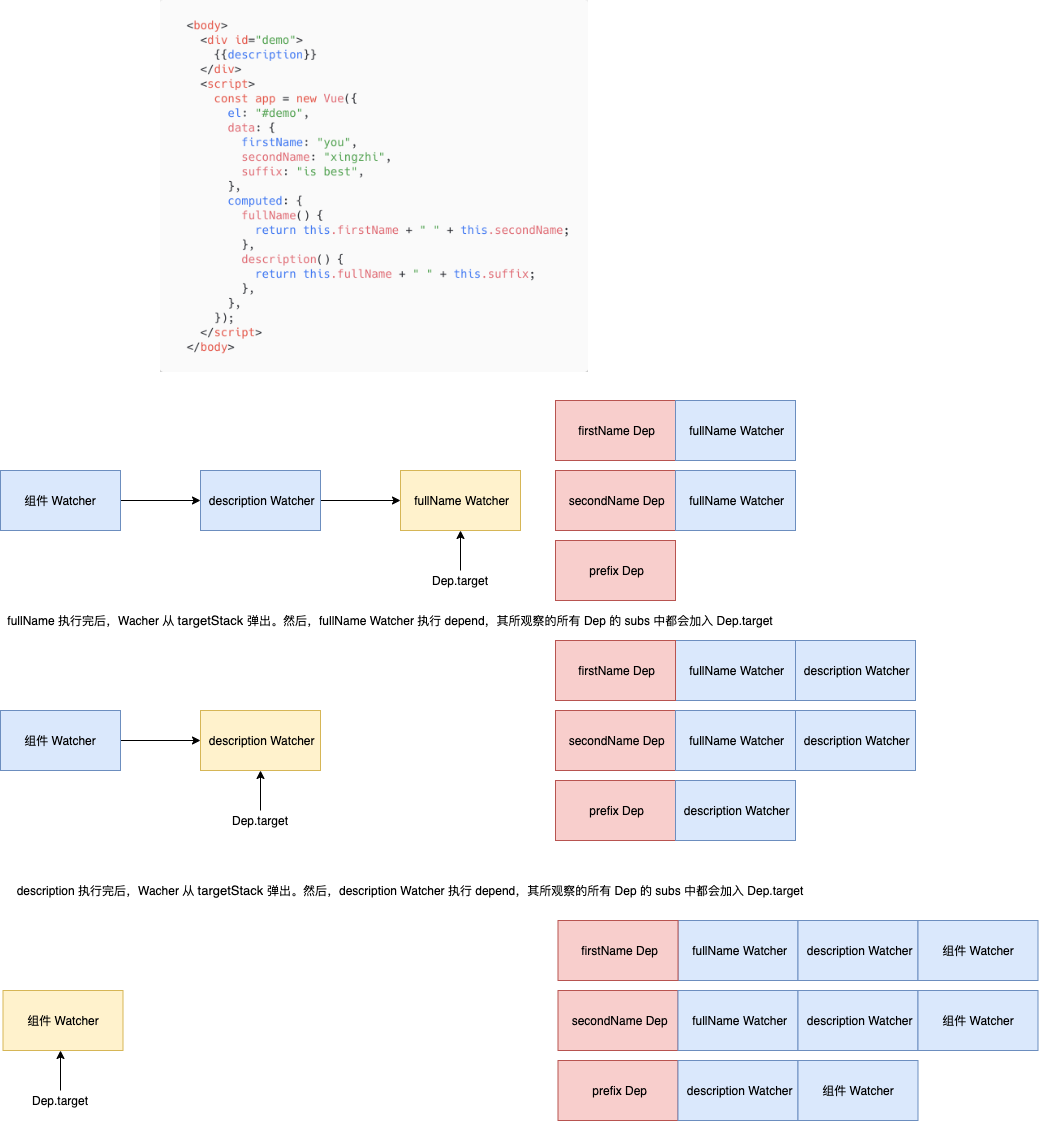
首次渲染的时候组件会实例化一个 Watcher 对象,会触发对 description 的求值,这里又会实例化一个 Watcher,而 description 中对 fullName 进行求值,又会实例化一个 Watcher。这样就形成了一个依赖栈,靠近栈底的元素会依赖其上面的元素。
当执行 fullName 的时候,由于其依赖了 firstName 和 secondName,所以它会被添加进两者的 dep 中。收集完后会执行 popTarget(),此时 Dep.target 指向 description 的 Watcher,然后会执行 watcher.depend() 。注意这里的 watcher 还是 fullName 的,即 fullName 依赖啥,其他依赖 fullName 的也需要跟我有同样的依赖。举个例子:儿子依赖老爸,老爸是个啃老族依赖父母,所以孙子也间接依赖了爷爷奶奶。整下的就举一反三了。
我们调试下代码,发现跟我们的分析是相符的: