前言
我用飞书和 AI 对话已经有一段时间了。这件事听起来简单,背后其实需要一套完整的基础设施:消息要能收发、对话上下文要能持久化、agent 执行环境要足够安全。
OpenClaw 是这个领域最知名的开源项目,功能相当完整。但当我真正想搞清楚它是怎么工作的时候,发现这几乎是不可能的事——数十个 Channel、跨平台客户端、语音唤醒、Canvas、多进程架构,代码量和依赖规模都远超你能在一个下午读完的范围。软件跑在我的机器上,我却完全不知道它在干什么。
NanoClaw 就是为了解决这个问题而生的。它提供了相同的核心能力,但整个 codebase 小到一个下午就能通读。
接下来我们从整体架构开始,到一条消息的完整旅程,再到各个模块的细节,一起把它拆开来看。
一、整体架构
NanoClaw 是一个单 Node.js 进程,内部分三层:
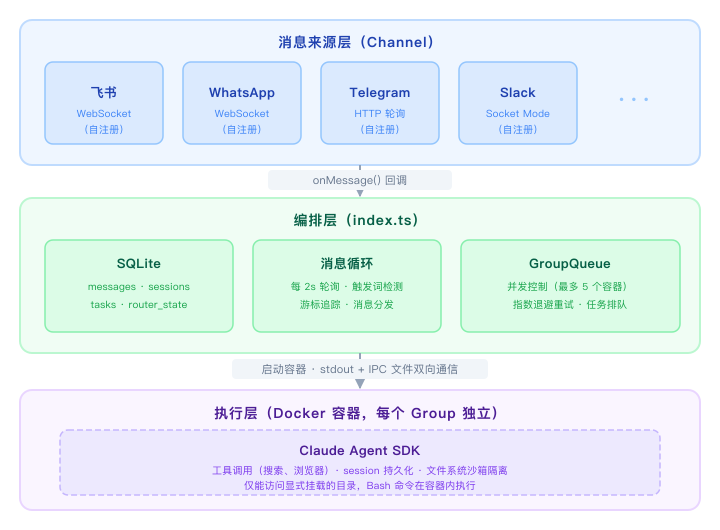
几个关键概念先说清楚:
Group(群组):每个注册的对话就是一个 Group。比如你的飞书私聊是一个 Group,一个工作群是另一个 Group。每个 Group 有独立的记忆文件(CLAUDE.md)、独立的工作目录、独立的对话 session,互不干扰。同一个 Group 同时只跑一个容器;全局最多 5 个容器并发,超出的进等待队列,有槽位自动补上。失败会指数退避重试,最多 5 次。
Channel:消息来源的抽象。飞书、WhatsApp、Telegram 都是 Channel,各自实现同一套接口,启动时自注册进来。你不需要哪个 Channel,代码里就没有它的任何痕迹。
容器:每次 agent 处理消息,都在一个独立的 Linux 容器里执行。容器只能看到明确挂载进去的目录,bash 命令跑在容器内,不影响宿主机。
二、一条消息的完整旅程
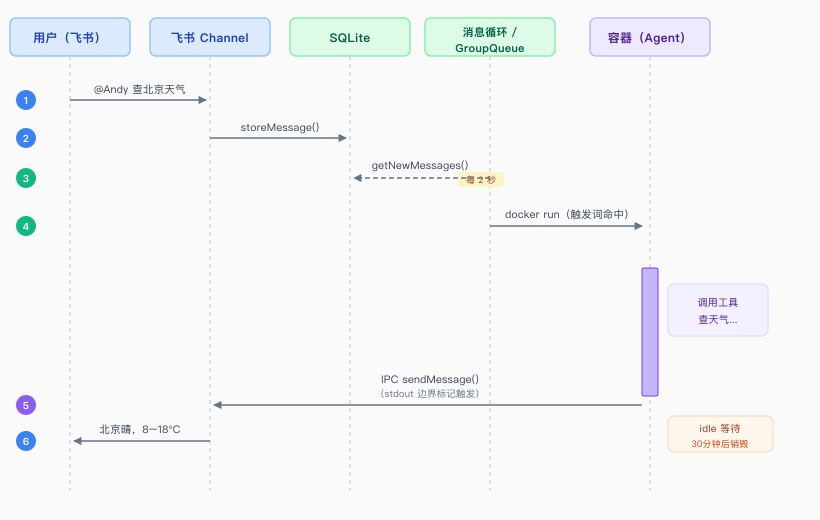
用一个具体例子串起全流程:在飞书里发一条消息 帮我查一下深圳天气。
2.1 飞书 Channel 接收消息
飞书 Channel 用的是 WebSocket 长连接(Lark SDK 的 WSClient),消息实时推送过来,不需要轮询。
收到消息后,调用 onMessage() 回调,把消息写入 SQLite:
1 | // src/channels/feishu.ts |
此时消息已经在 SQLite 的 messages 表里了,等待被处理。
2.2 消息循环检测触发词
主进程里有一个每 2 秒轮询一次的消息循环:
1 | // src/index.ts |
实际日志里能看到这个过程:
1 | {"level":30,"time":"2026-03-30T10:37:17.545Z","count":1,"msg":"New messages"} |
2.3 组装 prompt,启动容器
触发词命中后,从 SQLite 拉取这个 Group 上次 agent 回复之后的所有消息(最多 10 条),组装成 XML 格式的 prompt:
1 | <context timezone="Asia/Shanghai" /> |
然后启动一个 Docker 容器:
1 | docker run -i --rm \ |
几个关键点:
- API key 永远不进容器:
ANTHROPIC_BASE_URL指向宿主机上的凭证代理(credential proxy),这是 NanoClaw 主进程启动时在 3001 端口开的一个 HTTP 服务。容器里的 Claude Agent SDK 以为自己在访问 Anthropic API,实际上所有请求都先到代理,代理把ANTHROPIC_API_KEY=placeholder替换成真实 key,再转发给 Anthropic。容器里的 agent 拿不到真实 key——即使被 prompt injection 攻击也无法泄露。 --add-host host.docker.internal:host-gateway:在容器的/etc/hosts里写一条记录,把host.docker.internal指向宿主机的 IP(Docker 网桥的网关地址)。macOS 上 Docker Desktop 会自动做这件事,Linux 上需要手动加。有了这条记录,容器才能通过host.docker.internal:3001访问到宿主机上的凭证代理。.env被/dev/null遮蔽:项目根目录是只读挂载的,但.env里有 secrets,用/dev/null覆盖挂载点,agent 读不到任何内容。- 只能看到挂载的目录:容器内没有宿主机的其他文件系统,agent 执行
bash命令也只影响容器内部。
2.4 Agent 处理,结果通过 stdout 返回
容器内 Claude Agent SDK 读取 prompt,开始处理(调用工具查天气等)。处理完成后向 stdout 打印边界标记:
1 | ---NANOCLAW_OUTPUT_START--- |
NanoClaw 主进程(Node.js)用 child_process.spawn 执行 docker run 命令,通过 stdout pipe 实时监听输出。不需要等容器退出——每次检测到完整的标记对,立刻解析 JSON 并回复用户:
1 | // src/container-runner.ts |
回复发出后,容器并不退出,而是进入 idle 状态继续监听 input/ 目录。下一条消息到来时直接注入,容器无缝处理,标记对再次出现,用户收到新的回复。30 分钟无活动后容器才自动销毁。
用边界标记而不是直接解析最后一行,是因为 Claude Agent SDK 本身也会向 stdout 打印东西(工具调用日志、思考过程等),两个标记能精准定位真正的输出,不会被噪声干扰。
2.5 完整时序图
三、各模块详解
3.1 Channel 层:统一接口,自注册
所有 Channel 实现同一套接口:
1 | // src/types.ts |
每个 Channel 在模块加载时自注册,主进程统一 connect。以飞书为例,用的是 Lark SDK 的 WebSocket 长连接,不需要暴露公网端口,连接稳定:
1 | // src/channels/feishu.ts |
不同 Channel 的传输方式各不相同:
| Channel | 传输方式 |
|---|---|
| 飞书 | WebSocket(Lark WSClient) |
| Slack | WebSocket(Socket Mode) |
| WebSocket(Baileys) | |
| Telegram | HTTP 长轮询 |
| Gmail | HTTP 轮询 |
JID(Jabber ID)是跨 Channel 的统一标识符。飞书群的 JID 格式是 feishu:{chat_id},Telegram 是 telegram:{chatId},所有路由逻辑都用 JID 而不是 Channel 原始 ID。
3.2 消息编排:SQLite + 游标机制
消息存入 SQLite 的 messages 表后,消息循环通过游标来追踪处理进度:
lastTimestamp:全局游标,记录最后一次”看到”哪条消息lastAgentTimestamp[chatJid]:每个 Group 的游标,记录 agent 上次处理到哪条
两个游标分开是有原因的:消息”看到”和”处理完”是两件事。主进程先推进全局游标(防止重复检测),agent 处理完后才推进 Group 游标。如果 agent 出错,Group 游标回滚,下次会重新处理。
两个游标都持久化在 SQLite 的 router_state 表里,进程重启后从数据库恢复,不会丢失处理进度。
3.3 宿主-容器通信(IPC)
这是整个系统最精妙的部分——宿主机和容器完全通过文件系统通信,不走网络。
容器启动时,data/ipc/{folder}/ 目录被挂载进来:
1 | data/ipc/main/ |
宿主 → 容器:两种路径
路径 A:启动容器时通过 stdin 传入初始 prompt(一次性)。
路径 B:容器运行期间,新消息通过文件写入 input/ 目录。容器内的 agent-runner 定期轮询这个目录,发现文件立刻读取并注入 agent:
1 | // src/group-queue.ts |
关闭信号也是文件:写一个空的 _close 文件,容器收到后优雅退出。
容器 → 宿主:三种路径
路径 A:最终结果通过 stdout 的边界标记:
1 | ---NANOCLAW_OUTPUT_START--- |
路径 B:发送消息给用户,写 messages/ 目录:
1 | { |
路径 C:创建定时任务,写 tasks/ 目录:
1 | { |
宿主的 IPC watcher 每秒扫描 messages/ 和 tasks/,处理完立刻删除文件。
3.4 会话与记忆
容器是临时的——idle 30 分钟后会被销毁。但对话不能因此断掉。NanoClaw 把”记忆”分成三层来解决这个问题。
第一层:NanoClaw 的调度记忆(SQLite)
轮询、触发词检测、多消息合并——这些都发生在 Claude 介入之前。SQLite 的 messages 表存的是原始消息文本,router_state 表存的是游标,这两张表是 NanoClaw 自己的调度中枢,Claude 根本不知道它们的存在。
第二层:Claude 的对话记忆(SDK session)
Claude Agent SDK 把完整的对话历史存成 .jsonl 文件,每个 session 有一个唯一 ID。NanoClaw 把这个 sessionId 持久化在 SQLite 的 sessions 表里:
1 | $ sqlite3 store/messages.db "SELECT group_folder, session_id FROM sessions;" |
对应的文件就在磁盘上:
1 | data/sessions/main/.claude/projects/-workspace-group/ |
这个格式和你本机安装的 Claude Code 完全一样——Claude Code 把 session 存在 ~/.claude/projects/{工作目录}/ 下,NanoClaw 的 session 存在容器挂载的 data/sessions/{folder}/.claude/projects/ 下,都是同一套 Claude Agent SDK 的标准格式,只是挂载路径不同。NanoClaw 没有自己实现任何对话持久化,而是直接复用了 Claude Code 本身的能力。
容器销毁时,.jsonl 文件还在磁盘上,sessionId 还在 SQLite 里。下次消息到来,新容器启动,NanoClaw 把 sessionId 传给 SDK,SDK 读取对应的 .jsonl 文件,对话无缝继续——Claude 看到的是一条从未中断的对话。
第三层:人设与背景知识(CLAUDE.md)
每个 Group 还有一个 groups/{folder}/CLAUDE.md,在容器启动时作为系统提示读入。我的主群 CLAUDE.md 里定义了 Agent 的能力范围、回复风格。你也可以直接在飞书里告诉 Agent「记住我在深圳,平时早上 8 点前不要主动打扰我」,Agent 会把这些写进 CLAUDE.md,之后每次容器启动都会读到。
3.5 定时任务
Agent 可以通过 IPC 文件给自己或其他 Group 创建定时任务。支持三种调度类型:
| 类型 | 例子 | 说明 |
|---|---|---|
cron |
0 9 * * * |
每天早上 9 点 |
interval |
3600000 |
每小时(毫秒) |
once |
2026-04-01T09:00:00Z |
指定时间执行一次 |
主进程的 scheduler 每 60 秒扫描 scheduled_tasks 表,对到期任务启动独立容器执行,结果写回 task_run_logs。
比如你告诉 Agent「每天早上 9 点给我发天气预报」,agent 会写一个 IPC 文件到 tasks/,主进程创建任务记录,之后每天定时触发,不需要你再做任何事。
四、NanoClaw vs OpenClaw
有了前面的架构理解,再来看两者的差异就很具体了。
| OpenClaw | NanoClaw | |
|---|---|---|
| 代码量 | 比较庞大 | 几千行,一个下午能通读 |
| 架构 | Gateway 守护进程 + 多客户端 | 1 个 Node.js 进程 |
| 安全隔离 | 应用层白名单、设备配对 | OS 层容器隔离 |
| Agent 执行环境 | 同一进程,直接访问系统资源 | 独立 Linux 容器,只看挂载目录 |
| 定制方式 | 配置文件 | fork + 改代码 |
安全这一块值得多说一句。OpenClaw 的 agent 跑在主进程里,如果 agent 被诱导执行了恶意命令(比如 prompt injection),它实际上能访问你机器上所有 OpenClaw 有权限访问的东西。
NanoClaw 的 agent 跑在容器里,bash 命令执行的是容器内的 bash。即使 agent 被欺骗,它也只能动容器内挂载的那几个目录,出不了沙箱。
Skill 机制是另一个值得说的差异。NanoClaw 的功能扩展不是往主仓库加代码,而是维护在独立的 git 分支上。不需要的功能,代码里完全不存在。
以 Gmail 集成为例。在你的 fork 里对 Claude Code 说 /add-gmail,Claude Code 会:
- 把
nanoclaw-gmail仓库加为 git remote,fetch 并 merge 对应分支 - Merge 带进来的改动:
src/channels/gmail.ts(GmailChannel 实现)、barrel 文件里的 import、容器挂载配置(~/.gmail-mcp)、agent 侧的 MCP server 配置 - 引导你完成 GCP OAuth 授权,把凭证写到
~/.gmail-mcp/ - 重新构建容器镜像,重启服务
整个过程 Claude Code 全程操作,你只需要在浏览器里点一次 OAuth 授权。之后 agent 就能读邮件、发邮件,或者在收到新邮件时主动触发对话——取决于你选了 tool 模式还是 channel 模式。
如果你之后不想要 Gmail 了,反向操作:删掉 gmail.ts、移除挂载和 MCP 配置、重建容器。代码回到没有任何 Gmail 痕迹的状态。
当然,NanoClaw 也有明显的局限:
- 固定延迟:消息循环每 2 秒轮询一次,加上容器 cold start,响应速度不如常驻进程方案
- 维护负担:定制靠 fork,上游有更新时需要自己 merge,冲突自己解决
- 只支持文本:图片、文件、语音需要自己扩展 channel 实现
- 没有管理界面:查任务、改配置、看日志全靠命令行
- 不支持 Thread:Group 以
chat_id为粒度,Slack、飞书等应用里的 thread 消息和主频道消息会混入同一个 session,agent 无法对不同 thread 保持独立上下文 - 不适合规模化团队部署:全局最多 5 个容器并发,超出排队;单进程单机,没有高可用方案;所有群组共享同一套权限,没有角色和审计机制。几个人共用一个群聊完全没问题,但如果你想给一个组织的几十个群同时提供服务,这套架构撑不住
这些局限大多是”简单”这个目标的代价。如果你需要毫秒级响应、多媒体支持、或者企业级的权限管控,NanoClaw 不是合适的选择。