前言
随着大语言模型(LLM)能力的快速提升,AI Agent 已经从概念走向实践。然而,如何让 Agent 更可靠、更高效地完成复杂任务,成为开发者面临的关键挑战。
就像软件工程中的设计模式为常见问题提供了经过验证的解决方案,Agent 开发同样需要成熟的设计模式来指导实践。本文介绍五种核心模式:ReAct 通过推理与行动的交替循环处理需要外部信息的任务,CodeAct 通过生成代码应对复杂计算,计划模式为结构化任务提供清晰执行路径,反思模式通过迭代改进提升输出质量,人机协作模式在关键节点引入人工判断。
本文将深入介绍这五种核心 Agent 设计模式,通过理论讲解与实战案例,帮助你快速掌握每种模式的工作原理、适用场景和实现要点。
一、ReAct 模式
1.1 什么是 ReAct
ReAct(Reasoning + Acting)是一种将推理(Reasoning)和行动(Acting)相结合的 Agent 设计模式。它的核心思想是让 LLM 在解决问题时,不是一次性给出答案,而是模拟人类的思维过程:边思考、边行动、边观察结果,然后继续思考。
这种模式特别适合处理需要外部信息或工具支持的任务。通过将复杂问题分解为多个”思考-行动-观察”的小步骤,Agent 能够逐步逼近最终答案,整个过程更加透明、可控。
1.2 工作流程
ReAct 的核心流程可以概括为一个循环:Thought → Action → Observation → Thought。在每次循环中,Agent 首先进行思考阶段,分析当前问题和已有信息,决定下一步需要采取什么行动。例如,当需要查询股票价格时,Agent 会思考”我需要查询青岛啤酒的股票收盘价”。
接着进入行动阶段,Agent 选择合适的工具并指定参数,如 Action: get_closing_price 和 Action Input: {"name": "青岛啤酒"}。工具执行后进入观察阶段,将执行结果反馈给 Agent,例如 Observation: 67.92。Agent 收到观察结果后,会判断问题是否已经解决。如果未解决,则继续下一轮思考-行动-观察循环;如果已解决,则输出最终答案。
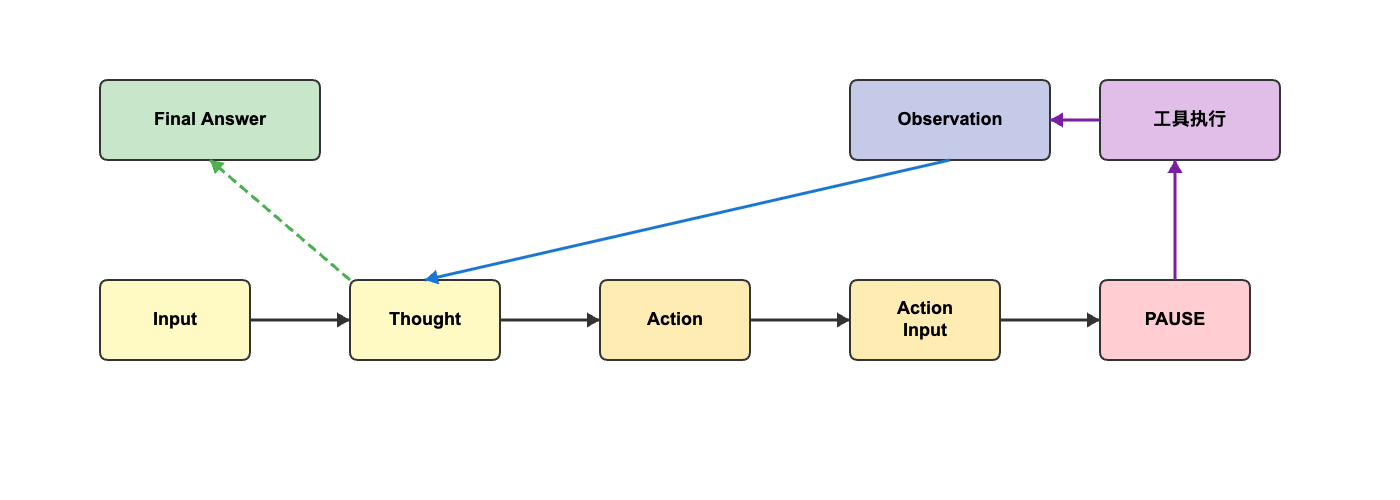
流程图展示了 ReAct 的完整执行过程。在底部的主流程中,Input 经过 LLM 推理后依次生成 Thought、Action、Action Input 和 PAUSE 标记。PAUSE 触发工具执行,执行结果形成 Observation 并返回给 LLM,由此形成一个闭环。当 LLM 判断已获得足够信息时,会从 Thought 节点输出 Final Answer,结束整个流程。
1.3 实战案例
案例:比较两个股票的收盘价
任务: 请比较青岛啤酒和贵州茅台的股票收盘价谁高?
核心代码实现
1. 工具定义与注册
1 | // 工具定义(JSON Schema 格式) |
2. Prompt 模板(关键部分)
1 | const REACT_PROMPT = ` |
3. Agent 主循环(核心逻辑)
1 | async function reactAgent(query: string) { |
Agent 的执行逻辑相对简单直接。首先用 Prompt 模板初始化消息,将工具列表和用户问题注入其中。然后进入主循环,不断调用 LLM 直到出现 Final Answer 标记。在每次循环中,解析 LLM 输出的 Action 和 Action Input,从工具注册表中找到对应的工具函数并执行,最后将执行结果作为 Observation 反馈给 LLM,开启下一轮循环。
运行结果示例
1 | 第一轮: |
1.4 使用 Function Call 来实现
前面展示的是经典的 ReAct 模式实现,需要通过 Prompt 让 LLM 输出特定格式(Thought/Action/Observation),然后手动解析这些文本。而现代 LLM API 都支持 Function Calling(函数调用),这让 ReAct 的实现变得更简单、更可靠。
核心代码实现
1. 工具定义(标准 OpenAI 格式)
1 | import {ChatCompletionTool} from 'openai/resources/chat/completions' |
2. Agent 主循环(Function Call 版本)
1 | async function functionCallAgent(query: string) { |
1.5 使用 LangGraph 实现
对于复杂的 Agent 场景(需要记忆、反思、人工介入等),LangGraph 提供了声明式的图结构定义,更易于维护和扩展。
LangGraph 将 Agent 建模为状态图,其中节点代表执行具体任务的函数,边定义节点之间的转换规则,而状态则是在各个节点之间传递的数据。这种抽象让 Agent 的执行流程更加清晰可控。
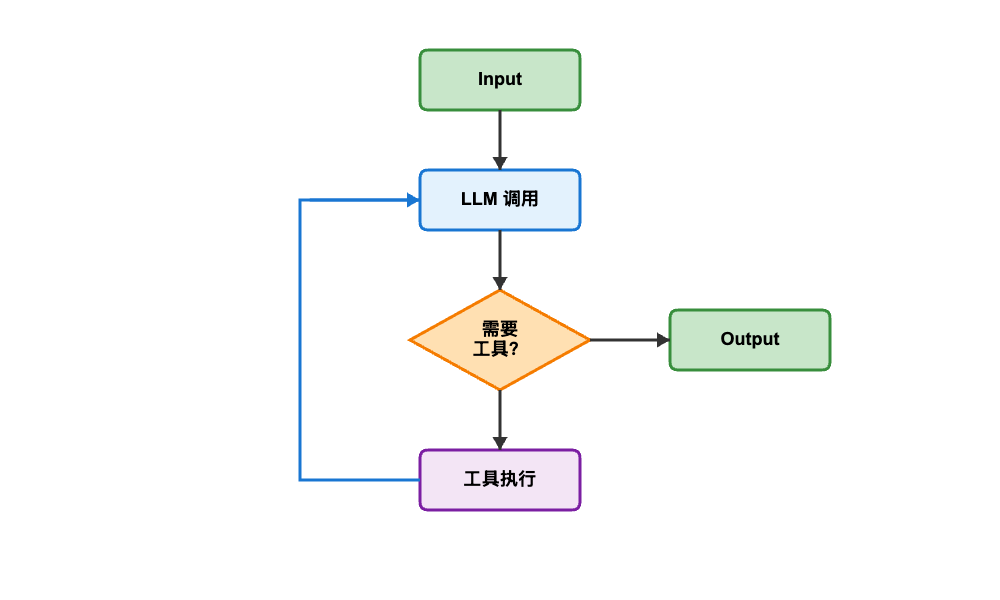
核心代码
构建图:
1 | import {StateGraph, END} from '@langchain/langgraph' |
其实 @langchain/langgraph 提供了 createReactAgent,可以更加方便的实现类似功能:
1 | import {createReactAgent} from '@langchain/langgraph/prebuilt' |
1.6 适用场景
ReAct 模式特别适合需要外部信息或工具支持的任务。当问题无法仅凭 LLM 内部知识解决时,比如查询实时数据、调用 API、执行计算等,ReAct 通过工具调用弥补了 LLM 的能力边界。这种模式对于多步骤推理任务也很有效,Agent 可以逐步收集信息、分析结果、调整策略,最终得出答案。同时,ReAct 的透明性让整个推理过程可观察可调试,便于理解 Agent 的决策逻辑。
1.7 注意事项
实现 ReAct 模式时需要注意几个关键点。Prompt 设计至关重要,需要清晰地定义 Thought、Action、Observation 的格式,并提供足够的示例帮助 LLM 理解预期输出。工具描述要准确明确,让 LLM 能够正确选择和使用工具。同时要设置合理的迭代次数上限,避免陷入无限循环。错误处理机制也不可忽视,当工具调用失败或 LLM 输出格式错误时,需要有恰当的降级策略。此外,要注意 Token 消耗,因为每次迭代都会增加消息历史的长度。
二、CodeAct 模式
2.1 核心理念
CodeAct(Code as Action)让 Agent 通过生成并执行代码来完成任务。与 ReAct 调用预定义工具不同,CodeAct 赋予 Agent 更大的灵活性,特别适合复杂计算、数据处理或需要组合多个操作的场景。核心流程是:Thought → Code Generation → Code Execution → Observation。
2.2 工作流程
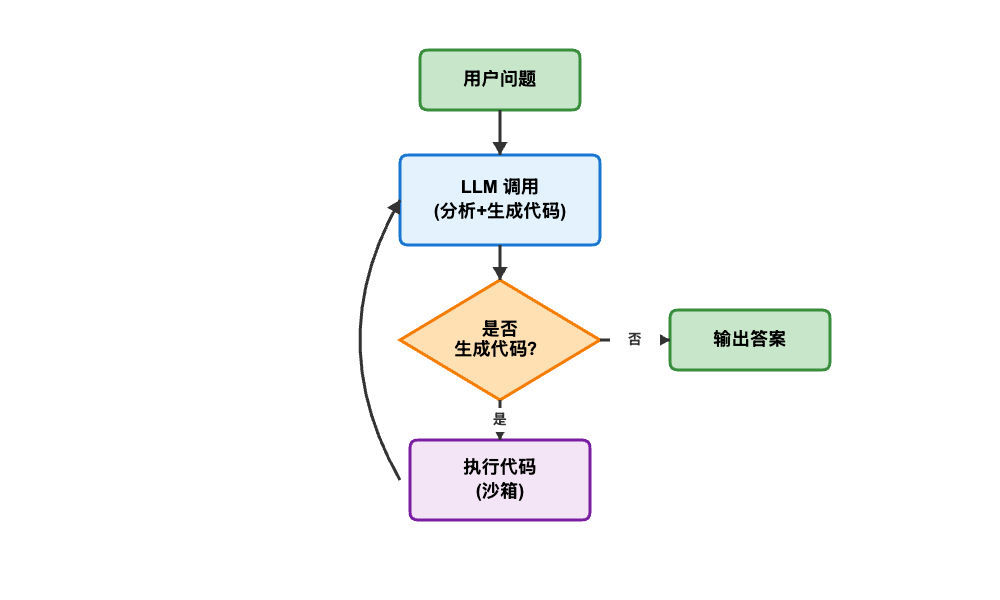
CodeAct 的执行流程从 LLM 分析用户问题开始,理解需要完成什么任务。接着 LLM 生成对应的代码(通常是 Python 或 JavaScript),这些代码会在沙箱环境中执行以保证安全性。执行结果作为 Observation 返回给 LLM,LLM 根据结果判断是继续生成新代码完善方案,还是已经得到满意答案可以结束流程。
2.3 实战案例
需求: 计算 1~100 的和
核心代码
1. 提示词(Prompt)
1 | // prompts.ts |
2. 工具(代码执行器)
1 | // tools.ts |
3. Agent 逻辑(LangGraph)
1 | // graph.ts |
4. 运行
1 | const agent = buildCodeActGraph() |
运行效果
1 | [启动 CodeAct Agent] |
从结果可以看到,大模型并没有使用循环,而是用等差数列求和公式来实现的,有点聪明的样子。
2.4 适用场景
CodeAct 模式特别适合需要灵活处理数据或进行复杂计算的场景。当任务涉及数学计算、数据转换、文本处理、算法实现等需要编程逻辑的操作时,生成代码往往比调用预定义工具更加高效和灵活。同时,对于需要组合多个操作或处理非标准化数据的任务,CodeAct 也展现出明显优势。这种模式让 Agent 不再局限于现有工具的能力边界,可以根据具体需求动态生成解决方案。
2.5 注意事项
使用 CodeAct 模式时必须高度重视安全性问题。代码执行必须在沙箱环境中进行,避免恶意代码对系统造成破坏。建议使用 vm 模块或 Docker 容器等隔离机制,并设置执行超时限制防止无限循环。此外,生成的代码质量依赖于 LLM 的能力,可能存在语法错误或逻辑错误,需要完善的错误处理机制。对于生产环境,还应该记录所有执行的代码以便审计和调试。
三、计划模式(Plan Mode)
3.1 核心理念
计划模式采用”先计划,后执行”的策略。ReAct 每步都需重新思考,适合探索性任务;计划模式则在开始时制定完整方案再逐步执行,更适合结构化程度高的任务。优势在于执行路径清晰、便于监控进度和预测资源消耗。但灵活性较低,初始计划不准确时可能需要人工调整。
3.2 工作流程
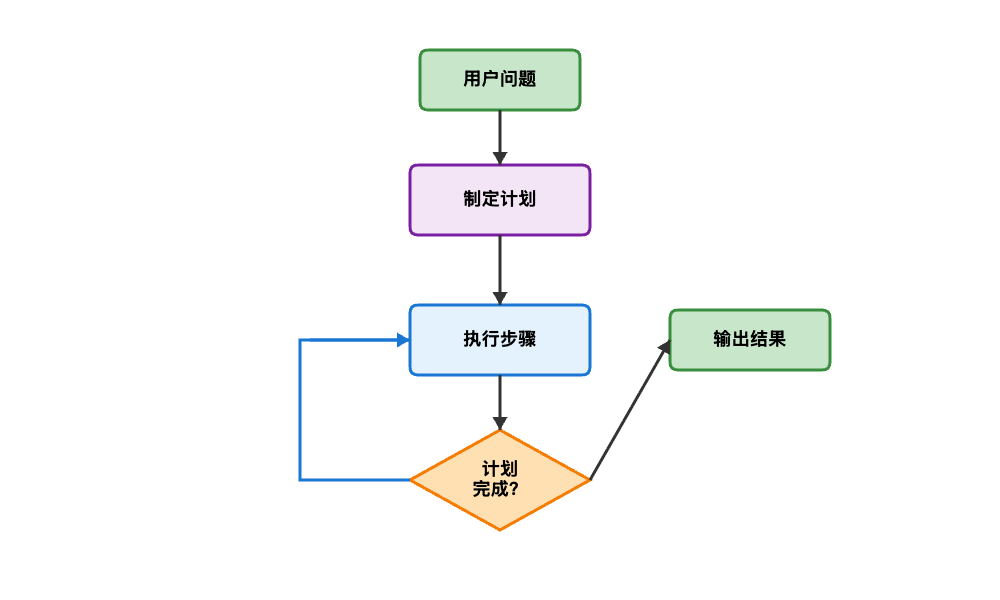
3.3 实战案例:简单计划模式
需求: 比较茅台和青岛啤酒哪个贵?
核心代码
1. 计划生成提示词
1 | // prompts.ts |
2. 状态定义
1 | // types.ts |
3. 工作流构建
1 | // graph.ts |
运行效果
1 | [启动计划模式 Agent] |
3.4 高级计划模式:动态调整
简单计划模式的局限是计划一旦生成就固定不变。高级计划模式引入了动态重新规划能力,可以根据执行结果调整剩余步骤,下面我们来改进一下。
工作流程
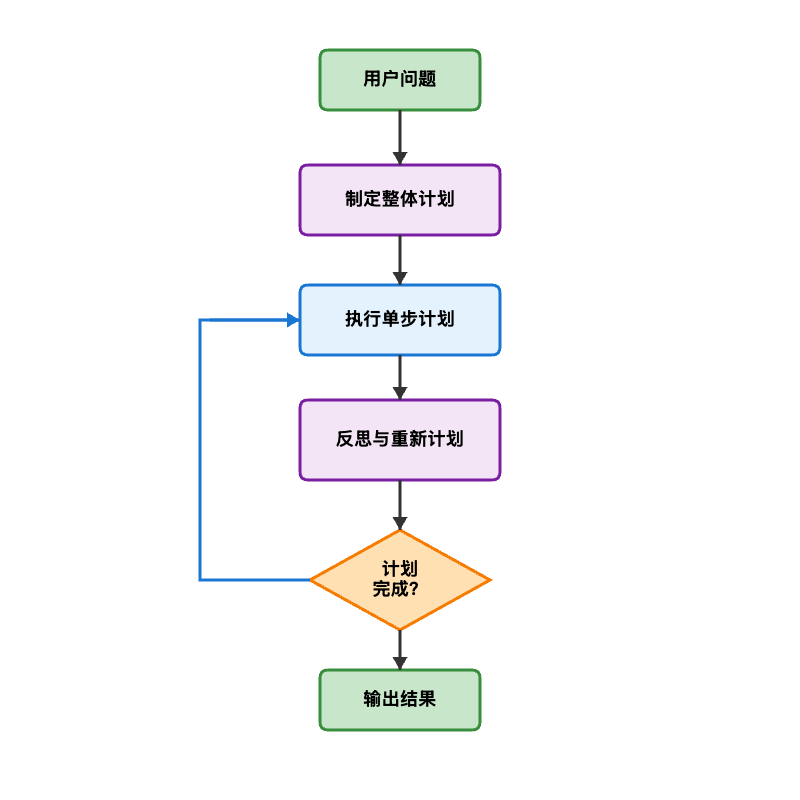
代码示例
1. Prompt 设计
1 | // 执行助手 Prompt(用于 ReAct Agent) |
2. 执行节点(使用 ReAct Agent)
1 | import {createReactAgent} from '@langchain/langgraph/prebuilt' |
3. 规划评估节点(核心:动态调整)
1 | // 规划评估节点 |
4. 构建 LangGraph 工作流
1 | import {StateGraph, END} from '@langchain/langgraph' |
运行示例(体现动态调整)
故意给一个不完整的初始计划,让 Agent 根据中间结果动态补充步骤。
1 | [启动高级计划模式 Agent] |
3.5 适用场景
计划模式最适合需求明确、步骤可预测的结构化任务。当任务目标清晰、可分解为多个具体步骤时,先制定计划再执行能够提供更好的可控性和可预测性。这种模式特别适合数据分析、报告生成、多步骤查询等场景。对于需要监控执行进度或预估完成时间的任务,计划模式的优势更加明显。同时,当需要优化执行顺序或并行处理某些步骤时,有了明确的计划更容易进行调度优化。
3.6 注意事项
使用计划模式需要权衡灵活性和可控性。如果任务的不确定性较高,初始计划可能不够准确,需要考虑引入动态调整机制(如高级计划模式)。计划生成的质量直接影响最终效果,需要精心设计计划生成的 Prompt,提供清晰的指导和示例。执行过程中可能遇到计划中未预见的情况,需要有合适的异常处理策略。此外,过于详细的计划可能限制 Agent 的灵活性,而过于粗略的计划又可能起不到指导作用,需要根据具体任务找到平衡点。
四、反思模式(Reflection Mode)
4.1 核心理念
反思模式模拟人类”先写初稿,再反复修改”的创作过程,通过自我评估和迭代改进来提升输出质量。这种模式特别适合对输出质量要求较高的场景,通过引入一个独立的反思环节来审视当前方案的不足之处。
4.2 工作流程
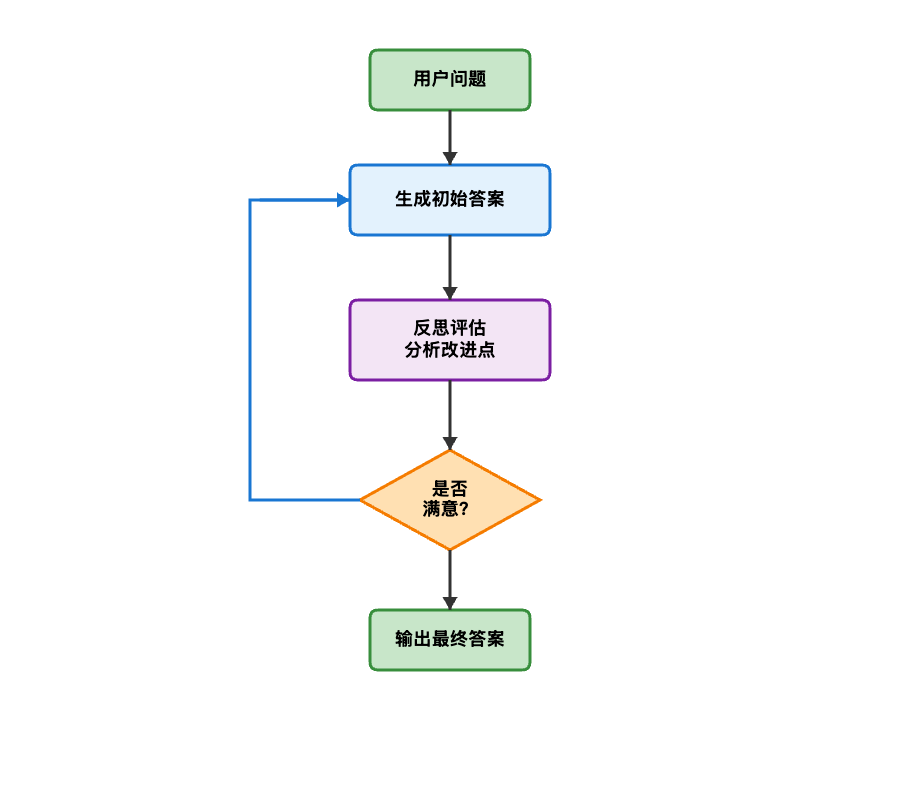
反思模式包含三个阶段的循环:生成阶段根据需求和反思建议生成方案,反思阶段多维度检查方案并提出改进建议,决策阶段判断是否继续优化。循环持续进行直到达到质量标准或迭代次数上限。
4.3 核心代码
反思模式的实现包含状态定义、Prompt 设计、生成节点、反思节点和决策函数几个关键部分。
状态定义:
1 | export const ReflectionState = Annotation.Root({ |
Prompt 设计:
反思模式的核心在于两个高质量的 Prompt。生成 Prompt 用于根据需求和反思建议生成或改进方案:
1 | export const COMMAND_PROMPT = `你是一个资深Linux运维专家,请根据用户需求生成最合适的Linux命令。 |
反思 Prompt 用于检查方案的合理性并提出改进建议:
1 | export const REFLECTION_PROMPT = `请严格检查以下Linux命令的合理性: |
结构化输出格式:
1 | import {z} from 'zod' |
生成节点:
1 | async function generateCommand(state: ReflectionStateType) { |
反思节点:
1 | async function reflectAndOptimize(state: ReflectionStateType) { |
决策函数:
1 | // 停止标志:发现这些关键词时立即停止 |
构建工作流:
1 | const workflow = new StateGraph(ReflectionState) |
4.4 运行示例
场景:生成 Docker 命令
1 | [启动反思模式 Agent] |
4.5 适用场景
反思模式最适合对输出质量有较高要求的场景。当需要生成文档、代码、配置文件、命令等关键输出时,通过反思机制可以显著提升方案的完整性和可靠性。这种模式特别适合技术方案设计、代码审查、内容创作等需要经过多次打磨才能达到专业标准的任务。同时,对于那些有明确质量评估标准的任务,反思模式能够系统性地检查各个维度是否达标。
4.6 注意事项
使用反思模式时需要注意控制迭代次数,避免过度优化导致效率低下或陷入无限循环。建议设置合理的迭代上限(通常 2-3 次即可),并定义清晰的停止条件。反思 Prompt 的设计至关重要,需要明确具体的检查维度和评估标准,避免模糊的评价导致反思效果不佳。此外,反思模式会增加 LLM 调用次数和 Token 消耗,需要在质量和成本之间做好平衡。对于某些已经足够好的初始方案,过度的反思可能反而引入不必要的修改。
五、人机协作模式(Human-in-the-Loop)
5.1 核心理念
人机协作模式将 Agent 的自动化能力与人类判断力相结合。适用于关键决策(高风险操作需人工确认)、信息补全(缺少参数时询问用户)和质量控制(重要输出需人工审核)等场景。通过在关键节点暂停执行、等待人工输入、然后恢复执行,实现效率与可控性的平衡。
5.2 工作流程
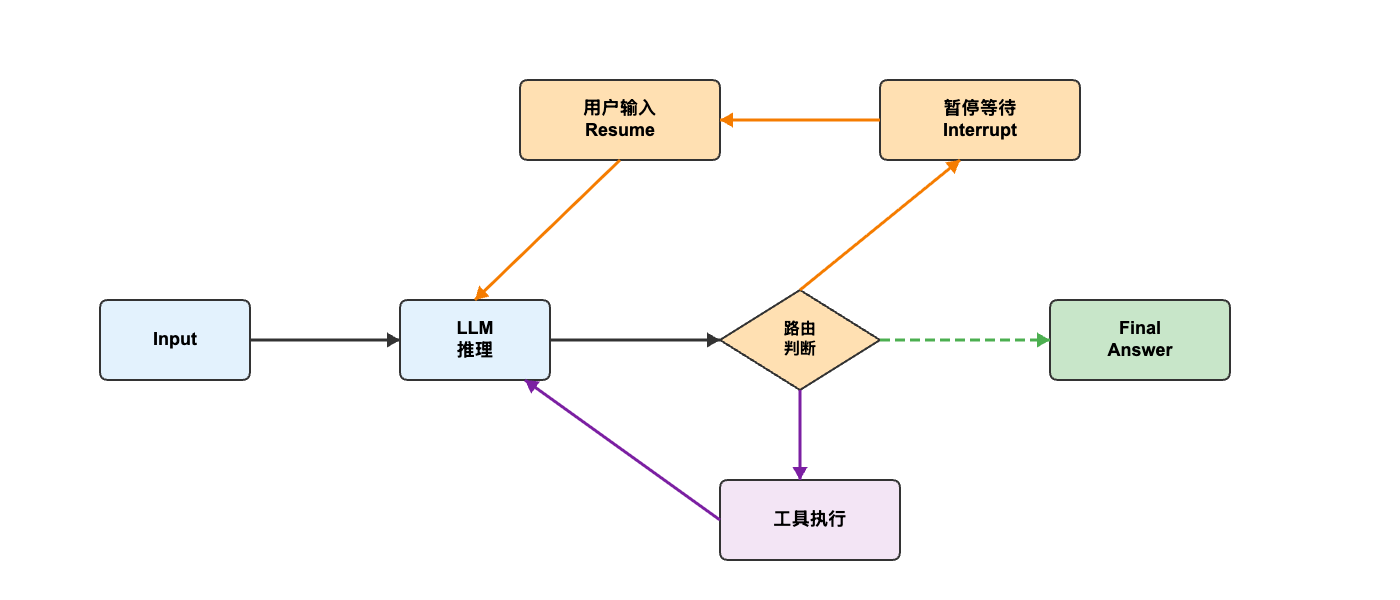
流程图展示了一个核心循环和三条分支路径:
核心循环:
1 | Input → LLM 推理 → 路由判断 |
分支 1:人工交互路径(橙色)
1 | 路由判断 → 暂停等待 → 用户输入 → LLM 推理(循环) |
- 触发条件:LLM 调用
ask_user工具 - 核心机制:
interrupt()暂停,等待用户输入,resume恢复 - 应用场景:缺少参数、需要用户确认、多选项决策
分支 2:工具执行路径(紫色)
1 | 路由判断 → 工具执行 → LLM 推理(循环) |
- 触发条件:LLM 调用普通工具
- 核心机制:自动执行工具,结果反馈给 LLM
- 应用场景:查询数据、计算处理、API 调用
分支 3:完成路径(绿色虚线)
1 | 路由判断 → Final Answer(结束) |
- 触发条件:LLM 判断已获得足够信息
- 核心机制:返回最终结果,结束执行
- 应用场景:问题解决、任务完成
实现依赖三个核心机制:中断机制通过 interrupt() 暂停执行并等待人工输入,状态保存机制使用 Checkpointer 保留所有上下文信息,恢复执行机制通过 Command({ resume: userInput }) 从暂停点继续执行。
5.3 实战案例:购物助手
场景: 用户询问购买商品的总价,但没有说明数量,需要询问用户。
核心代码实现
1. 工具定义
1 | import {tool} from '@langchain/core/tools' |
关键点:
ask_user是一个特殊工具,用于触发人工介入- LLM 会在需要用户信息时自动调用这个工具
2. 人工节点(核心)
1 | import {interrupt, Command} from '@langchain/langgraph' |
关键点:
interrupt()会暂停整个工作流的执行- 返回的值会在恢复执行时作为
resume参数传入 - 用户输入被封装成
ToolMessage返回给 LLM
3. 路由函数(识别触发时机)
1 | function enterTools(state: HumanLoopStateType): string { |
4. 构建 LangGraph(必须使用 Checkpointer)
1 | import {StateGraph, START, END} from '@langchain/langgraph' |
关键点:
- 人机协作模式必须配置
checkpointer MemorySaver将状态保存在内存中(生产环境可用数据库)
5. 运行 Agent(两阶段执行)
1 | export async function runHumanLoopAgent( |
关键点:
- 第一次
invoke会执行到interrupt处暂停 - 获取用户输入后,通过
Command({ resume: userInput })恢复 - 必须使用相同的
threadConfig才能恢复到正确的状态
运行效果
1 | [启动人机协作模式 Agent] |
5.4 适用场景
人机协作模式在多种场景下都能发挥重要作用。对于敏感操作,比如删除数据、修改配置、执行系统命令等高风险动作,在执行前需要用户明确确认。可以通过定义 confirm_operation 工具,在执行前暂停并向用户展示即将执行的操作内容,等待用户审核通过后再继续。
在信息补全场景中,当 Agent 发现缺少必需参数、需要用户在多个选项中选择、或参数含义不明确时,可以暂停执行并向用户询问。这种交互式的信息收集方式比让 Agent 自行猜测要可靠得多。
质量控制是另一个重要应用场景。当 Agent 生成文档、代码、方案等内容后,可以暂停执行让用户审核输出质量。在关键决策点,人工判断往往比 LLM 的判断更可靠。此外,对于重要结果,在使用前进行人工验证可以避免潜在风险。
异常处理场景也很常见。当 Agent 遇到无法自动处理的情况时,与其直接失败不如暂停并请求人工帮助。用户可以提供额外信息、调整策略或从多个备选方案中选择,然后 Agent 继续执行。
5.5 高级用法
1. 支持多轮人工介入
1 | async function runWithMultipleInterrupts(query: string) { |
2. 支持用户取消
1 | const userInput = await getUserInput() |
3. 添加超时处理
1 | const timeout = (ms: number) => |
5.6 注意事项
实现人机协作模式时需要注意几个关键点。首先,必须配置 Checkpointer 来保存状态,这是整个模式的技术基础。可以选择 MemorySaver 用于开发和简单场景,或使用 SqliteSaver 等持久化方案用于生产环境。
Thread ID 的一致性至关重要。恢复执行时必须使用与暂停时相同的 thread_id,否则会导致状态丢失。在多用户场景下,务必为每个用户会话分配独立的 thread_id 以隔离状态,避免数据混淆。
输入验证不可忽视。用户可能输入无效内容、格式错误或超出预期范围的数据,需要实现完善的验证和错误处理机制。同时,应该设置合理的超时机制,避免 Agent 无限期等待用户输入。提供取消操作的选项也很重要,让用户可以随时中止流程。
六、总结
五种 Agent 设计模式各有侧重。ReAct 通过推理-行动循环适合处理需要外部工具的任务,CodeAct 通过代码生成解决复杂计算问题。计划模式提供结构化执行路径,简单版适合明确任务,高级版支持动态调整。反思模式通过迭代优化提升输出质量,人机协作模式在关键节点引入人工判断确保可控性。
实际应用中往往需要组合使用。建议从简单模式开始验证核心逻辑,逐步引入高级特性。根据任务特点权衡性能与准确性,同时做好日志监控和安全防护。通过理解这些模式的特点和适用场景,你可以构建高效可靠的 Agent 系统。