引言
当 AI 能够生成大量代码时,一个新问题随之而来:如何量化团队对 AI 的依赖程度?为了回答这个问题,我构建了一套统计系统,用于追踪和分析仓库中 AI 代码的占比。代码见 https://github.com/ParadeTo/ai-stats
快速开始
1. 安装与启动
安装 Cursor 插件:
克隆本项目后,在 Cursor 编辑器中打开插件目录并安装,插件会自动配置钩子以捕获 AI 生成的代码。
安装依赖:
系统分为后端和前端两个部分,需要分别安装依赖:
1 | # 后端服务 |
配置环境变量:
在 server 目录下创建 .env 文件,配置 GitHub 访问令牌:
1 | GITHUB_TOKEN=your_github_token_here |
启动服务:
1 | # 启动后端服务(端口 3001) |
启动成功后,访问 http://localhost:3000 即可看到系统主界面。
2. 基本使用流程
步骤 1:使用 AI 生成代码并推送到 GitHub
在 Cursor 编辑器中使用 AI 生成代码。系统会自动捕获这次 AI 生成的差异并存入数据库。完成开发后,将代码提交并推送到 GitHub。
重要提示:只有在代码推送到 GitHub 后,系统才能在项目列表页展示该仓库的分析数据。
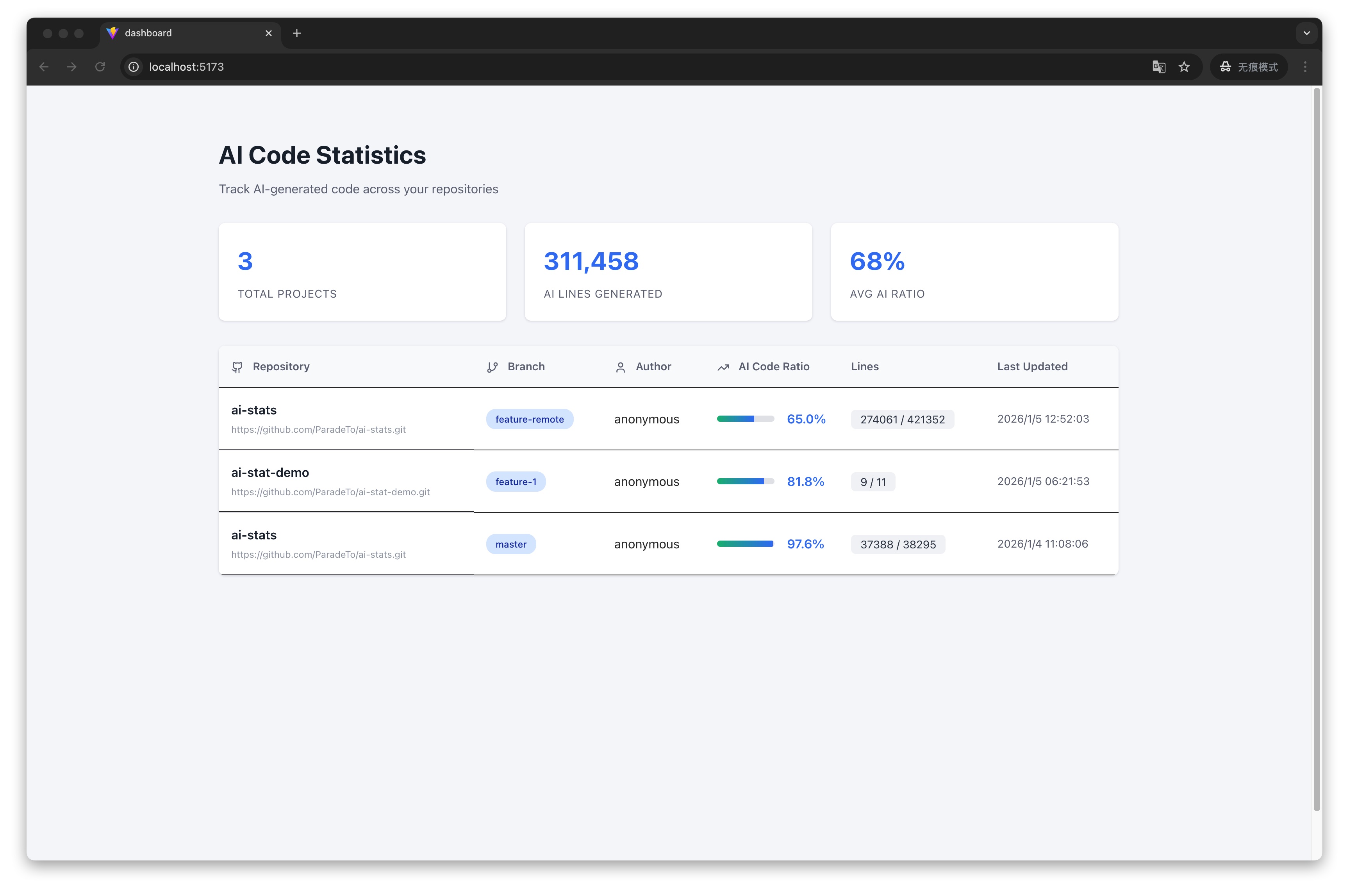
步骤 2:查看列表
代码推送到 GitHub 后,打开系统主界面,即可以看到分析的数据:
步骤 3:查看详情
点击项目,进入详情页面:
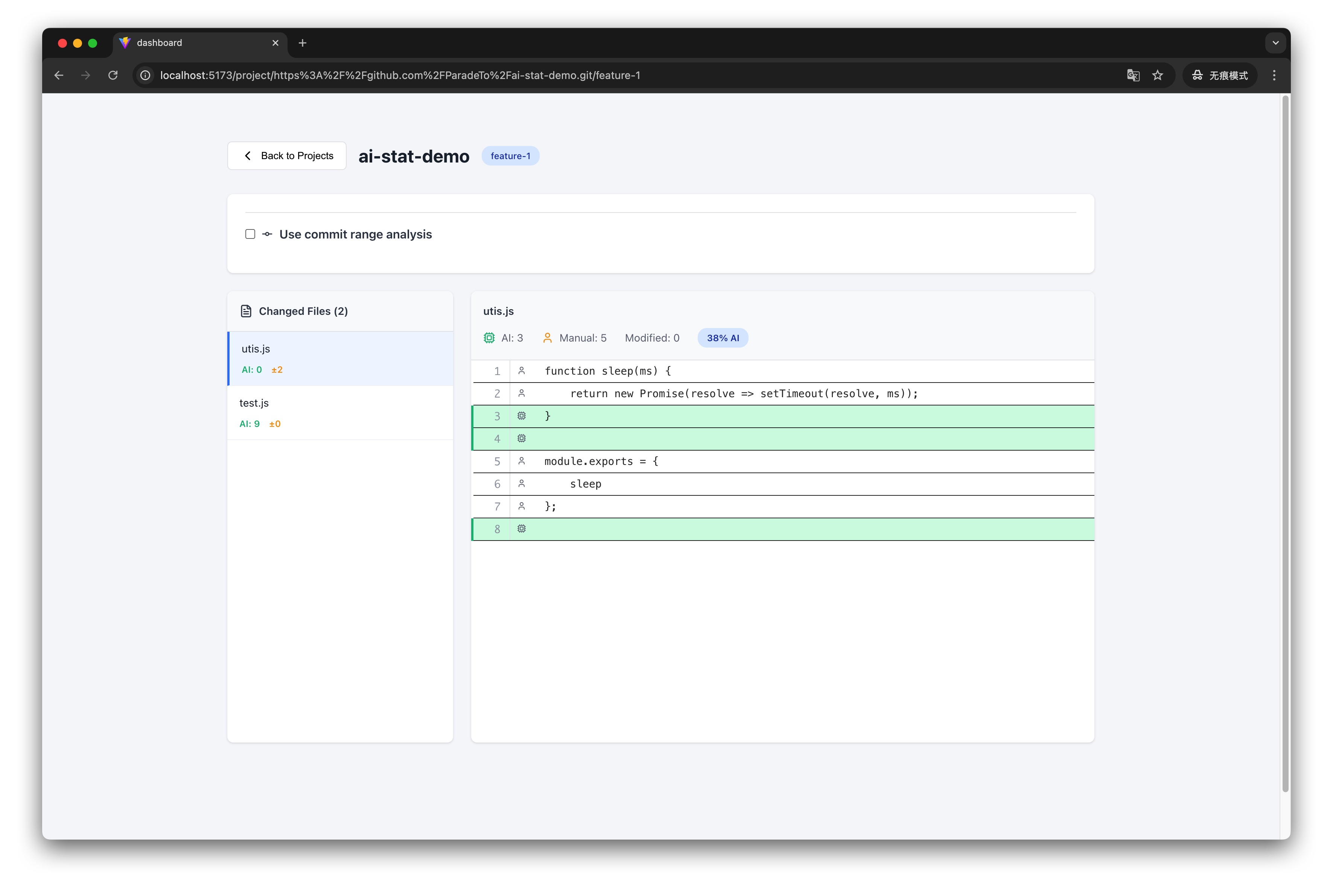
查看代码归属:
点击左侧的文件,系统会展示文件内容,每一行代码都标注了归属:
- 绿色背景:AI 生成
- 白色背景:人工编写
- ● 标记:有未保存的手动标记
- ✓ 标记:已保存的手动标记
- ⚠ 标记:手动标记已失效(内容已变更)
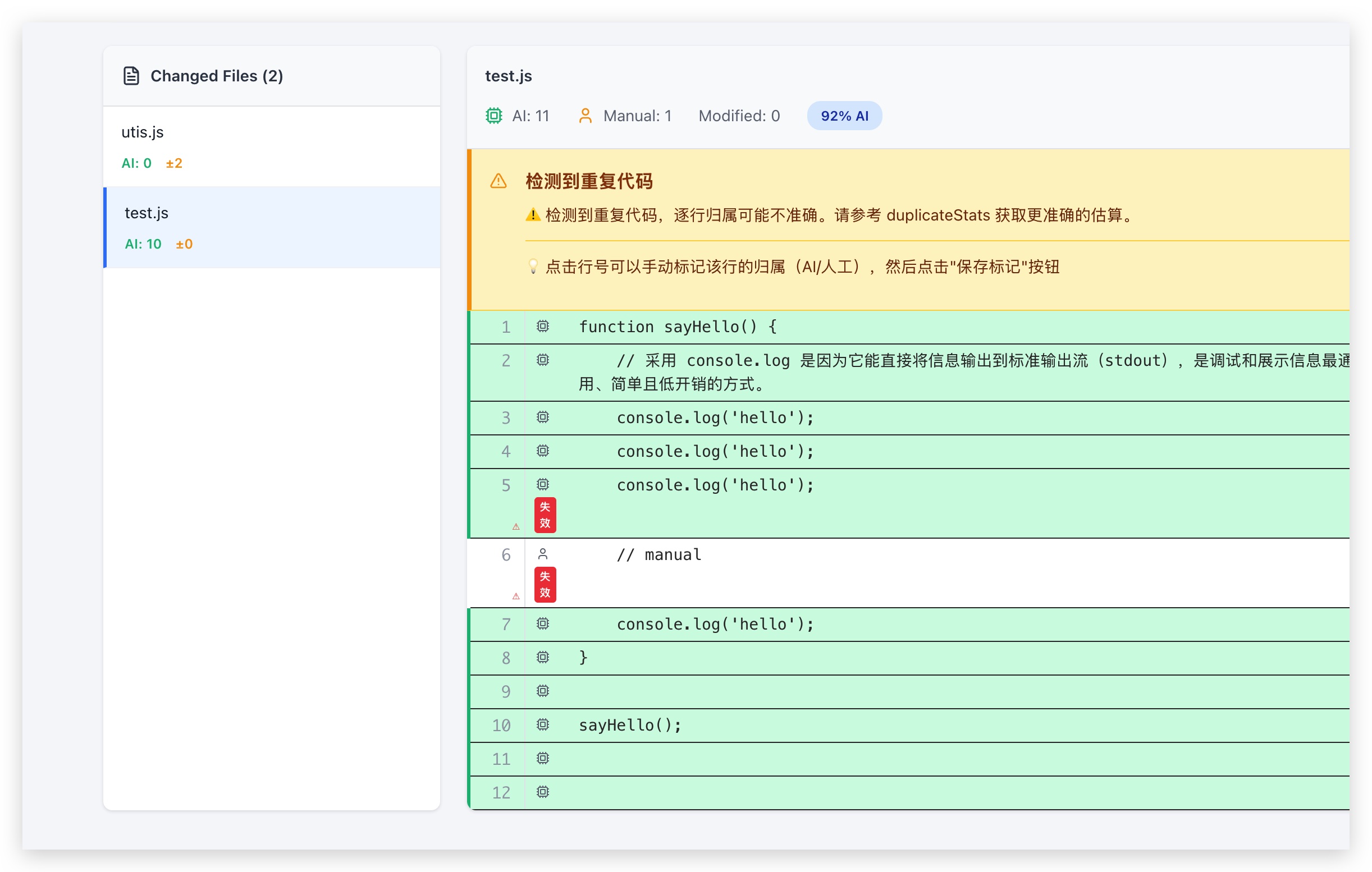
处理重复代码警告:
如果文件中存在多行相同的代码,系统会在顶部显示警告信息,例如:
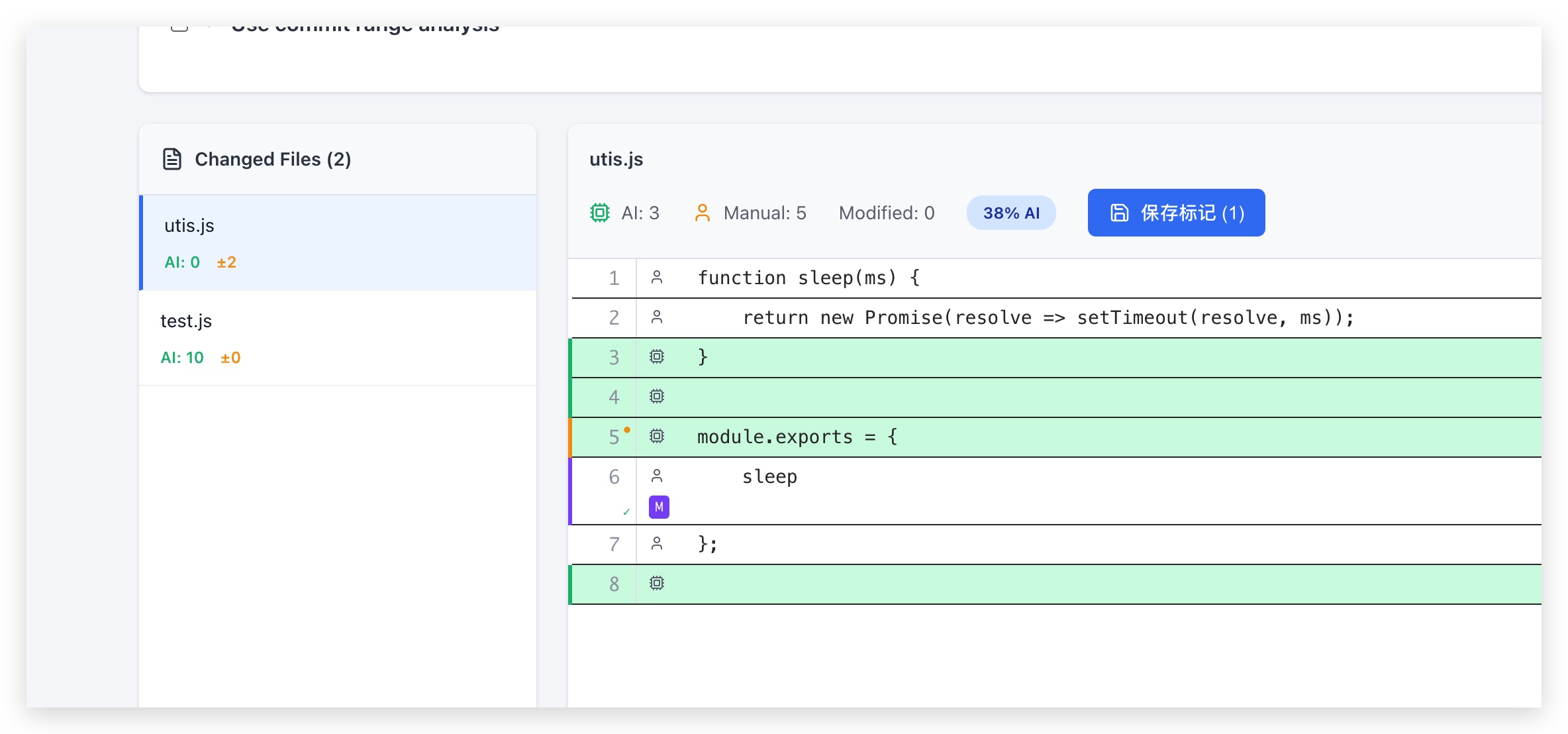
步骤 4:手动标记
对于系统无法准确判断的代码(如重复代码),可以手动标记。点击代码行号,该行的归属会在 AI/人工之间,点击页面顶部的”保存手动标记”按钮。
手动标记会存储在数据库中,并在后续所有分析中优先使用。
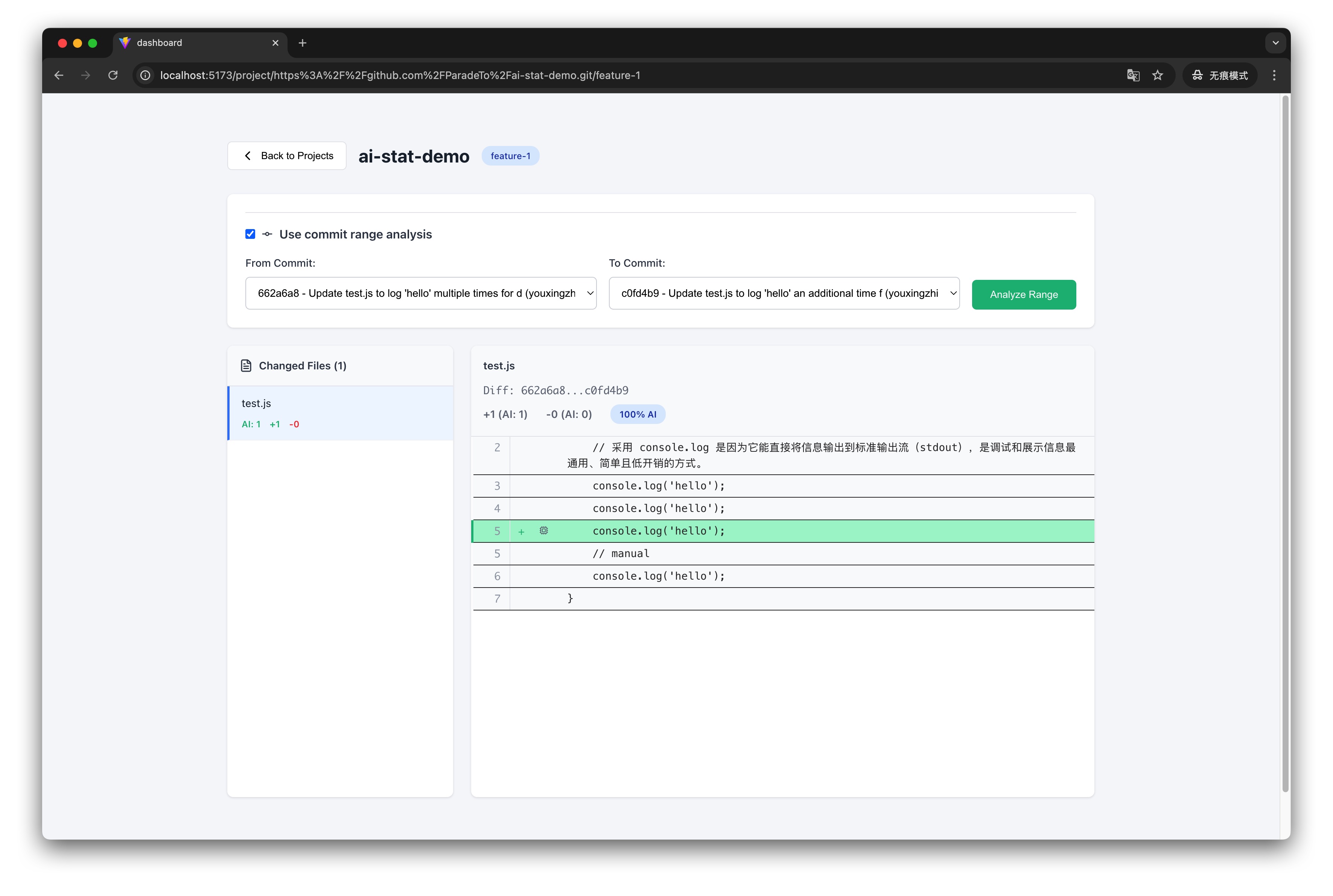
步骤 5:Commit 范围分析
如果需要分析特定 commit 范围内的代码变更,可以:
- 勾选”使用 commit 范围分析”
- 输入起始 commit 和结束 commit 的哈希值
- 点击”分析”
系统会展示该范围内的所有变更,并标注每一行的增删状态和 AI 归属。
以下章节将详细介绍系统的技术实现原理。
系统架构概览
AI 代码追踪系统采用三层架构设计,分别是插件层、后端层和前端层。每一层承担不同的职责,共同构成了完整的追踪链路。
系统架构图
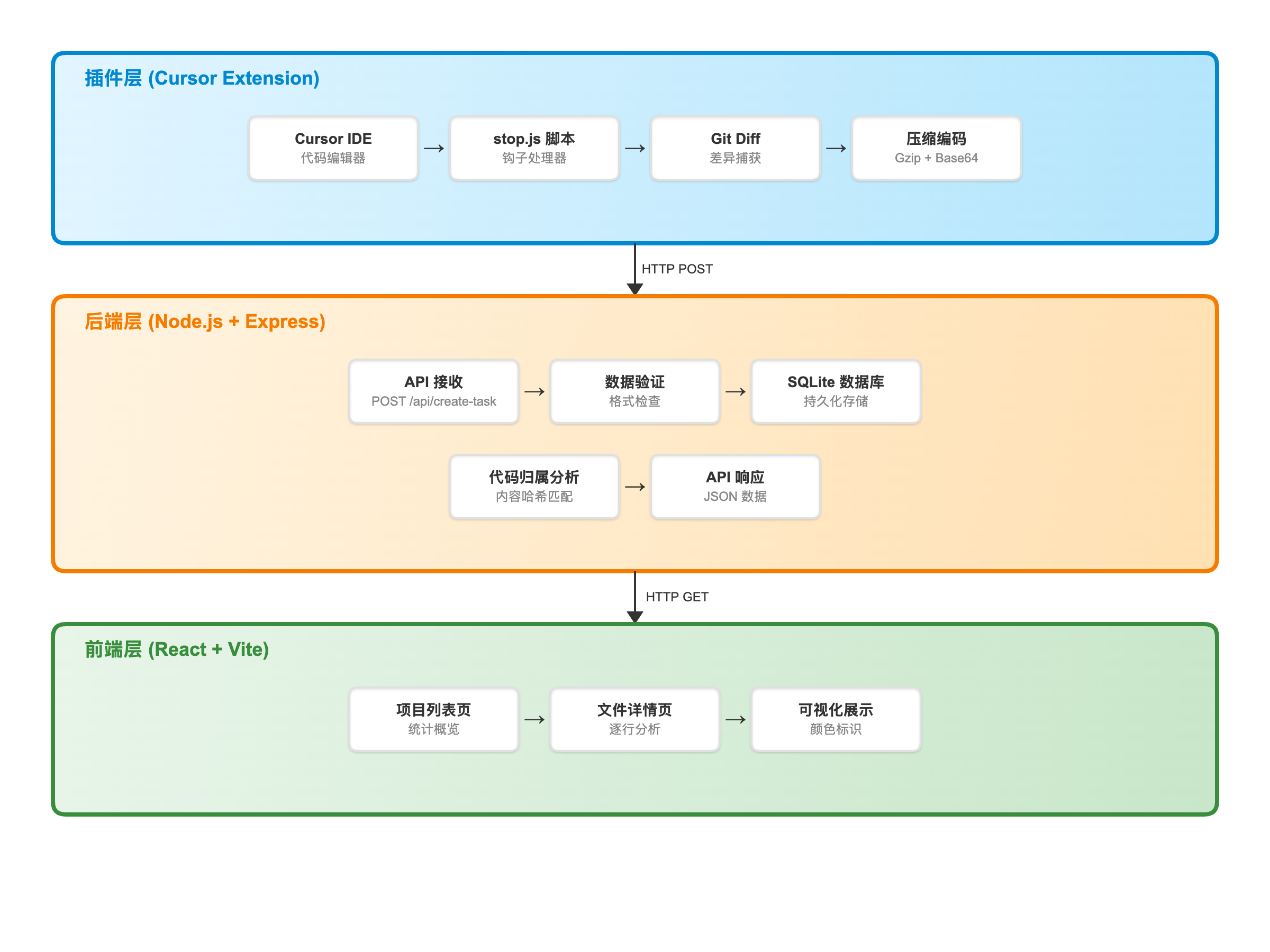
插件层:实时捕获机制
插件层是整个系统的数据入口,它的核心任务是准确捕获 AI 生成的代码。
Cursor 钩子系统
Cursor 编辑器提供了生命周期钩子机制,允许开发者在特定事件发生时执行自定义脚本。系统通过修改 Cursor 的配置文件 ~/.cursor/hooks.json 来注册钩子:
1 | { |
核心钩子是 stop,它在每次 AI 代码生成完成且用户点击”应用”按钮时被触发。当钩子被触发时,Cursor 会通过标准输入流向脚本传递一个 JSON 对象,包含丰富的元数据:
1 | { |
这些元数据为后续的数据分析提供了重要的上下文信息。
stop.js 脚本的工作流程
stop.js 脚本是插件层的核心组件,它执行以下步骤来完成数据捕获:
1. 读取元数据
脚本首先从标准输入读取 Cursor 传入的元数据:
1 | const cursorData = await readStdin() |
关键技术细节:脚本需要从元数据中提取 workspace_roots 字段,这个字段包含了用户项目的本地路径,用于后续的 Git 操作。
2. 获取 Git 差异
这里需要处理两种情况:
情况 A:已跟踪文件的修改
1 | git diff |
情况 B:未跟踪的新文件
Git 默认不会将未跟踪的新文件包含在差异中。系统使用 git add -N 命令将新文件临时标记为”意图添加”状态:
1 | // 获取未跟踪的文件 |
3. 压缩和传输
获取到差异后,脚本进行压缩处理:
1 | // 压缩差异数据(通常能减少到原来的 10-20%) |
完整捕获示例
场景:开发者小李在 Cursor 中请求 AI 生成一个快速排序函数。
步骤 1:AI 生成代码
1 | function quickSort(arr) { |
步骤 2:小李点击”应用”按钮,stop.js 脚本被触发
步骤 3:脚本执行 git diff,获取差异
1 | diff --git a/utils.js b/utils.js |
步骤 4:脚本压缩、编码并发送到后端
1 | { |
步骤 5:后端存储到数据库,完成捕获
后端层:存储与分析算法
后端层是整个系统的核心,它不仅要存储数据,更重要的是提供智能的分析能力。
数据库设计
后端使用 SQLite 数据库存储 AI 代码生成记录。表结构设计如下:
1 | -- AI 代码生成记录表 |
存储示例:
1 | INSERT INTO task_records VALUES ( |
压缩后的差异数据以 Base64 编码的字符串形式存储。当需要分析时,系统会:
- 从数据库读取 Base64 字符串
- 解码为二进制数据
- 使用 Gzip 解压缩,还原为原始 diff 文本
- 使用 parse-diff 库解析 diff,提取出每一行代码
核心算法:内容哈希匹配
系统识别 AI 代码的核心算法基于内容哈希匹配。这个算法的设计经过了多次迭代优化,最终形成了一套完整的解决方案。
算法原理
基本思想:为每一行代码计算一个唯一的哈希值(”指纹”),通过比较哈希值来判断代码的来源。
哈希计算:
1 | function hashLine(line) { |
示例:
1 | hashLine(' return true;') // → "a3f5e9d2b1c8f4e1" |
AI 代码索引数据结构
系统使用 Map(映射)数据结构来存储 AI 生成的代码信息。可以把它理解为一个”字典”,通过代码的”指纹”(哈希值)来查找这行代码的详细信息。
基本结构:
1 | const aiLinesMap = new Map() |
字段详解:
| 字段 | 类型 | 说明 | 示例 |
|---|---|---|---|
| 键(Key) | string | 代码行的哈希值,作为唯一标识 | "a3f5e9d2b1c8f4e1" |
| timestamp | string | AI 最早生成这行代码的时间 | "2024-01-15T10:00:00Z" |
| generation_id | string | 对应最早生成记录的 ID | "gen-123" |
| count | number | AI 生成这行代码的总次数 | 3 表示 AI 生成过 3 次 |
| occurrences | Array | 所有生成记录的完整列表 | 见下方示例 |
完整示例:
假设 AI 在不同时间多次生成了同一行代码 return true;:
1 | // 第一次生成(2024-01-15) |
存储在 Map 中的数据:
1 | aiLinesMap.set('hash(return true;)', { |
为什么要记录 timestamp(最早时间)?
让我用一个真实的开发场景来说明:
完整的开发时间线:
1 | // ============ 1月10日:你开始写项目 ============ |
问题来了:现在文件中有两行一模一样的 return new Promise(...)
- 第 1 行:你在 1 月 10 日写的
- 第 2 行:AI 在 1 月 15 日生成的
如果没有 timestamp,会发生什么?
1 | // 系统只知道:AI 生成过 return new Promise(...) |
有了 timestamp,系统怎么判断?
1 | // 第1行 return new Promise(...) |
总结:
timestamp 就像一个”时间戳”,告诉系统:
- “AI 是从 1 月 15 日开始知道这行代码的”
- “如果某行代码在 1 月 15 日之前就存在,那肯定不是 AI 写的”
- “如果某行代码在 1 月 15 日之后出现,那可能是 AI 写的”(也有可能 AI 写了,人工删除又添加回来了)
没有 timestamp,系统只能简单地认为”凡是内容相同的代码都是 AI”,这会错误地把你的劳动成果归给 AI。有了 timestamp,系统能区分”谁先写的”,避免误判。
为什么要记录 count?
用于检测重复代码问题。例如:
1 | // 场景:文件中有 5 行 return true; |
从数据库构建 AI 代码索引
目标:将数据库中存储的 AI 生成记录转换成一个可快速查询的索引结构。
输入:数据库中的 AI 生成记录(包含压缩的 diff 数据、时间戳等)
输出:Map<内容哈希, 元数据>,用于快速判断某行代码是否为 AI 生成
核心思路:
- 从数据库读取所有 AI 生成记录
- 解压每条记录的 diff 数据
- 提取所有新增的代码行
- 为每行代码计算哈希值
- 将哈希值和元数据(时间戳、生成次数等)存入 Map
系统通过 buildAiLinesMap 函数实现这个过程:
1 | function buildAiLinesMap(rows, zlib, parseDiff) { |
生成的 Map 结构示例:
1 | Map([ |
有了这个 Map,判断某行代码是否为 AI 生成就非常简单:
1 | const hash = hashLine('return true;') |
下面通过几个案例来进行说明。
案例 1:基本的代码归属分析
场景:分析一个包含 AI 和人工代码的文件。
数据库记录(2024-01-15 生成):
1 | // AI 生成的快速排序函数 |
当前文件内容(utils.js):
1 | // 工具函数集合 |
分析过程:
步骤 1:构建 AI 代码索引
1 | aiLinesMap = Map([ |
步骤 2:逐行分析文件
1 | 第1行: "// 工具函数集合" |
分析结果:
1 | { |
案例 2:时间过滤的局限性
场景:AI 生成的代码被删除后,人工重新添加了相同的代码。
时间线:
1 | 2024-01-15 10:00:00 AI 生成: return true; |
问题:如何区分这两次 return true; 的来源?
当前实现:使用时间过滤
1 | // 获取文件的最后修改时间 |
分析逻辑:
1 | const aiInfo = aiLinesMap.get(hash('return true;')) |
当前实现的局限性:
系统目前只使用时间戳进行简单比较,无法识别”删除 → 重新添加”的场景。
在案例的场景中(AI 生成 → 删除 → 人工重新添加),系统会:
- [正确识别] AI 在 1 月 15 日生成过
return true; - [误判结果] 1 月 17 日的
return true;也会被标记为 AI(因为时间戳满足条件) - [无法识别] 中间的”删除 → 重新添加”过程
改进方向:
- 需要结合 Git 历史分析(
git log --follow)追踪代码的删除和重新添加
案例 3:重复代码的处理
场景:文件中有多行相同的代码,但来源不同。
文件内容:
1 | function check1() { |
AI 记录:只有 1 次生成 return true;
问题:三行 return true; 的哈希值完全相同,如何判断?
算法处理:
步骤 1:统计文件中的重复代码
1 | const hashCounts = new Map() |
步骤 2:对比 AI 生成次数
1 | const aiInfo = aiLinesMap.get(hash('return true;')) |
步骤 3:生成警告和估算
1 | { |
设计理念:
当检测到重复代码时,系统采用”诚实报告”策略:
- 逐行归属(
analysis):基于哈希匹配,可能不准确(3 行都标记为 AI,存在误判) - 统计估算(
duplicateStats):基于 AI 生成次数,更接近真实情况(1 AI + 2 人工) - 警告信息(
warning):明确告知用户”逐行归属可能不准确”
系统不会强行猜测哪一行是 AI、哪一行是人工(因为这在技术上无法准确判断),而是提供多个维度的信息,让用户自己判断。这种设计比给出错误的精确结果更有价值。
手动标记功能:
为了解决重复代码等无法自动准确判断的场景,系统提供了手动标记功能:
- 交互方式:用户点击代码行号,即可切换该行的归属(AI ↔ 人工)
- 优先级:手动标记的优先级最高,会覆盖自动识别的结果
- 内容验证:通过内容哈希验证,确保标记的准确性
- 持久化:手动标记存储在数据库中,刷新页面后仍然有效
手动标记流程:
1 | // 1. 用户点击第 6 行的行号 |
选择”行号+内容匹配”的原因:
- 避免误匹配:重复代码场景下,用户只想标记特定一行,不应影响其他行
- 明确性:行号失效时会显示
manualInvalid: true,用户可以重新标记 - 可预测性:用户点击哪一行,就只影响那一行
案例 4:Commit 范围分析
场景概述:分析两个 commit 之间的代码变更,计算 AI 代码占比。
Commit 范围分析的核心是判断:在指定的 commit 范围内,哪些新增/删除是 AI 做的。这涉及三个关键数据结构:
allAiLines:历史上所有 AI 添加的代码(从数据库查询得到)allAiDeletes:历史上所有 AI 删除的代码(从数据库查询得到)aiLinesInRange:当前 commit 范围内 AI 添加的代码
aiLinesInRange 的构建过程:
通过两遍扫描 Git diff 来构建。第一遍扫描所有新增行,检查其哈希是否在 allAiLines 中,如果在就加入 aiLinesInRange:
1 | // 第一遍:识别当前 range 内 AI 添加的行 |
新增操作的判断逻辑:
1 | if (allAiLines.has(hash)) { |
删除操作的判断逻辑:
1 | if (allAiDeletes.has(hash)) { |
案例 4.1:aiLinesInRange 为空
代码演变过程
第 1 步(Commit A)- 基础代码
2024-01-10,小王手动创建了基础文件:
1 | // utils.js |
第 2 步(Commit B)- AI 添加功能
2024-01-15,AI 助手添加了防抖函数:
1 | // utils.js |
第 3 步(Commit C)- 小王简化 sleep
2024-01-20,小王觉得 sleep 函数太复杂,删除了 Promise 那行:
1 | // utils.js |
分析任务
小王想知道:从 Commit B 到 Commit C,这次改动中有多少是 AI 的贡献?
Git Diff(B → C)
1 | --- a/utils.js (Commit B) |
只有 1 行删除,没有新增。
系统分析过程
1 | // 步骤 1:找出 B → C 范围内,AI 新增了哪些代码 |
分析结果
1 | { |
案例 4.2:aiLinesInRange 不为空
代码演变过程
Commit A(起点)
2024-01-10,基础代码:
1 | // utils.js |
Commit B(终点)
2024-01-15,AI 重构代码:
1 | // utils.js |
从 Commit A 到 Commit B,AI 贡献了多少代码?
Git Diff(A → B)
1 | --- a/utils.js (Commit A) |
变更:
- 删除 1 行
- 添加 4 行
系统分析过程
步骤 1:找出 A → B 范围内,AI 添加了哪些代码
1 | const aiLinesInRange = new Set(); |
步骤 2:判断删除操作的归属
被删除的代码:return a + b;(旧的那行)
1 | const hash = hashLine('return a + b;'); |
分析结果
1 | { |
aiLinesInRange 的作用是识别 AI 在当前 commit 范围内”删除旧代码 + 添加相同内容新代码”的重构行为,将这类删除操作正确归属给 AI。如果没有这个数据结构,由于 allAiDeletes 中没有这行代码的删除记录,系统会将其误判为人工删除,导致统计结果出现偏差。
总结
AI 代码追踪系统通过”源头捕获 + 内容哈希匹配”实现 AI 代码的准确追踪。系统在 AI 生成代码的瞬间捕获差异,使用内容哈希识别代码,即使代码位置变化也能正确匹配。
不过整个系统还存在一些问题,可以做进一步优化的。
比如现在存在删除后重写的代码会被误判的问题。具体来说就是,当 AI 生成了一行代码,用户删除后又手动写回相同内容时,系统仍会将其标记为 AI 代码。这是因为当前只做内容哈希匹配,没有追踪代码的”生命周期”。后续可结合 git log --follow 分析代码的删除和重新添加历史,识别出”删除 → 人工重写”的场景。
还有目前系统仅支持单人使用,团队成员的追踪数据各自独立,无法聚合查看。后续可设计数据同步机制和权限管理,提供团队级别的统计视图。