前言
在 Agent 设计模式的演进中,我们已经见证了 ReAct 模式如何让 LLM 学会使用工具,Plan-and-Solve 模式如何提升复杂任务的规划能力。然而,当我们面对”分析 2025 年贵州茅台的投资价值”这样需要深度分析、多角度求证的复杂课题时,现有的模式往往显得力不从心。单次的搜索和总结往往只能提供浮于表面的信息,无法像人类分析师那样进行层层递进的深度挖掘。
Deep Research(深度研究) 模式正是为了解决这一痛点而生。它的核心理念在于迭代式研究(Iterative Research)。与传统的”搜索-总结”线性流程不同,Deep Research 引入了反思(Reflection)机制,模仿人类研究员的工作流:
- 广度优先(Breadth-First):先生成多个角度的初始查询,获取概览信息。
- 自我反思(Self-Reflection):阅读初步结果,像人类一样自问:”这些信息够了吗?还缺什么细节?”
- 深度挖掘(Depth-First):针对反思中发现的知识缺口(Knowledge Gap),生成具体的后续查询。
- 循环迭代:重复上述过程,直到信息充足或达到预定深度。
这种模式让 Agent 从单纯的”问答机器”进化为具备批判性思维的”研究助手”,能够主动识别信息的缺失并自主补全。本文将基于 LangGraph 实现这样一个完整的深度研究 Agent。
一、工作流程 (Workflow)
Deep Research 的典型工作流包含以下关键节点:
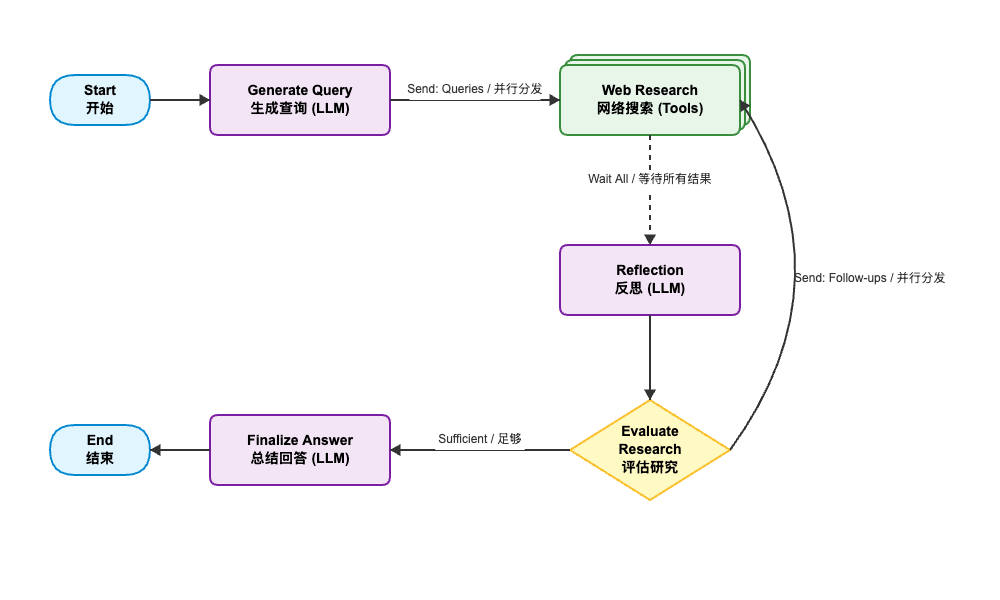
- Generate Query (生成查询): 将用户模糊的需求转化为多个具体的搜索引擎友好的查询词。
- Web Research (网络研究): 并行执行搜索,抓取网页内容。这是一个高并发的步骤,利用 Send 机制分发任务。
- Reflection (反思): 核心大脑。分析已收集的信息,判断是否满足需求。如果不满足,识别知识缺口,生成 Follow-up Queries(后续查询)。
- Evaluate (评估): 路由节点。决定是继续下一轮搜索(进入 Web Research),还是结束研究(进入 Finalize Answer)。
- Finalize Answer (输出报告): 综合所有轮次收集的信息,生成最终报告,并附上引用来源。
二、核心代码实现
我们使用 LangGraph 来编排这个复杂的状态机,使用 Tavily API 进行高质量搜索。
2.1 状态定义
首先定义 Agent 的”记忆”(State)。我们需要存储用户的原始问题、所有生成的查询、收集到的搜索结果、以及反思产生的知识缺口。
1 | // types.ts |
2.2 生成初始查询
Agent 的第一步不是直接搜索,而是”拆解问题”。
1 | // graph.ts (Generate Query Node) |
2.3 并行搜索执行
为了提高效率,我们并行执行搜索。这里利用了 LangGraph 的 Send 机制,将每个查询分发给独立的 web_research 节点运行。
1 | // graph.ts (Conditional Edge) |
2.4 核心:反思与知识缺口
这是 Deep Research 的灵魂。Agent 阅读所有已有的搜索结果,判断是否足够回答用户问题。
1 | // graph.ts (Reflection Node) |
2.5 决策路由
根据反思结果决定下一步。
1 | // graph.ts (Evaluate Node) |
三、实战案例:贵州茅台分析
我们使用一个真实的运行日志,展示 Agent 如何分析 “贵州茅台”。
1 | npx ts-node src/deep-research/index.ts "贵州茅台分析" |
四、总结
Deep Research 模式突破了传统 Agent 浅层搜索的局限,通过模仿人类研究员”广度探索-自我反思-深度挖掘”的迭代工作流,自动化地识别并填补知识缺口,从而能够自主完成从模糊需求到高质量深度研究报告的完整闭环,特别适用于行业调研、竞品分析等需要深度洞察的复杂场景。